
Tree are of various types:











struct node
{
int value;
struct node *left;
struct node *right;
int rthread;
}
node *inorder_successor(node *x)
{
node *temp;
temp = x->right;
if(x->rthread==1)return(temp);
while(temp->left!=NULL)temp = temp->left;
return(temp);
}
void inorder(node *head)
{
node *temp;
if(head->left==head)
{
printf("\nTree is empty!\n");
return;
}
temp = head;
for(;;)
{
temp = inorder_successor(temp);
if(temp==head)return;
printf("%d ", temp->value);
}
}
void insert(int item, node *x)
{
node *temp;
temp = getnode();
temp->value = item;
x->left = temp;
temp->left=NULL;
temp->right=x;
temp->rthread=1;
}
void insert_right(int item, node *x)
{
node *temp, r;
temp=getnode();
temp->info=item;
r=x->right;
x->right=temp;
x->rthread=0;
temp->left=NULL;
temp->right=r;
temp->rthread=1;
}
node *inorder_predecessor(node *x)
{
node *temp;
temp = x->left;
if(x->lthread==1)return(temp);
while(temp->right!=NULL)
temp=temp->right;
return(temp);
}
inorder = g d h b e i a f j c
preorder = a b d g h e i c f j
inorder = g d h b e i a f j c
postorder = g h d i e b j f c a
inorder = g d h b e i a f j c
level order = a b c d e f g h i j
A
B C
D E F G
a[1] a[2] a[3] a[4] a[5] a[6] a[7]
A B C D E F G // CONSTRUCTING A TREE GIVEN THE INORDER AND PREORDER SEQUENCE
#include <stdio.h>
#include <string.h>
#include <ctype.h>
/*-------------------------------------------------------------
* Algorithm
*
* Inorder And Preorder
* inorder = g d h b e i a f j c
* preorder = a b d g h e i c f j
* Scan the preorder left to right using the inorder to separate left
* and right subtrees. a is the root of the tree; gdhbei are in the
* left subtree; fjc are in the right subtree.
*------------------------------------------------------------*/
static char io[]="gdhbeiafjc";
static char po[]="abdgheicfj";
static char t[100][100]={'\0'}; //This is where the final tree will be stored
static int hpos=0;
void copy_str(char dest[], char src[], int pos, int start, int end);
void print_t();
int main(int argc, char* argv[])
{
int i,j,k;
char *pos;
int posn;
// Start the tree with the root and its
// left and right elements to start off
for(i=0;i<strlen(io);i++)
{
if(io[i]==po[0])
{
copy_str(t[1],io,1,i,i); // We have the root here
copy_str(t[2],io,2,0,i-1); // Its left subtree
copy_str(t[3],io,3,i+1,strlen(io)); // Its right subtree
print_t();
}
}
// Now construct the remaining tree
for(i=1;i<strlen(po);i++)
{
for(j=1;j<=hpos;j++)
{
if((pos=strchr((const char *)t[j],po[i]))!=(char *)0 && strlen(t[j])!=1)
{
for(k=0;k<strlen(t[j]);k++)
{
if(t[j][k]==po[i]){posn=k;break;}
}
printf("\nSplitting [%s] for po[%d]=[%c] at %d..\n", t[j],i,po[i],posn);
copy_str(t[2*j],t[j],2*j,0,posn-1);
copy_str(t[2*j+1],t[j],2*j+1,posn+1,strlen(t[j]));
copy_str(t[j],t[j],j,posn,posn);
print_t();
}
}
}
}
// This function is used to split a string into three seperate strings
// This is used to create a root, its left subtree and its right subtree
void copy_str(char dest[], char src[], int pos, int start, int end)
{
char mysrc[100];
strcpy(mysrc,src);
dest[0]='\0';
strncat(dest,mysrc+start,end-start+1);
if(pos>hpos)hpos=pos;
}
void print_t()
{
int i;
for(i=1;i<=hpos;i++)
{
printf("\nt[%d] = [%s]", i, t[i]);
}
printf("\n");
}
print_infix_exp(node * root)
{
if(root)
{
printf("(");
infix_exp(root->left);
printf(root->data);
infix_exp(root->right);
printf(")");
}
}
node *create_tree(char postfix[])
{
node *temp, *st[100];
int i,k;
char symbol;
for(i=k=0; (symbol = postfix[i])!='\0'; i++)
{
temp = (node *) malloc(sizeof(struct node));//temp = getnode();
temp->value = symbol;
temp->left = temp->right = NULL;
if(isalnum(symbol))
st[k++] = temp;
else
{
temp->right = st[--k];
temp->left = st[--k];
st[k++] = temp;
}
}
return(st[--k]);
}
float eval(mynode *root)
{
float num;
switch(root->value)
{
case '+' : return(eval(root->left) + eval(root->right)); break;
case '-' : return(eval(root->left) - eval(root->right)); break;
case '/' : return(eval(root->left) / eval(root->right)); break;
case '*' : return(eval(root->left) * eval(root->right)); break;
case '$' : return(eval(root->left) $ eval(root->right)); break;
default : if(isalpha(root->value))
{
printf("%c = ", root->value);
scanf("%f", &num);
return(num);
}
else
{
return(root->value - '0');
}
}
}
Case 1 - Design an algorithm and write code to find the first common ancestor of two nodes in a binary tree. Avoid storing additional nodes in a data structure. NOTE: This is not necessarily a binary search tree.
Case 2- What will you do if it is Binary search tree

class Node{
int value;
Node left;
Node right;
Node parent;
}
int getHeight(Node p) {
int height = 0;
while (p) {
height++;
p = p.parent;
}
return height;
}
// As root.parent is NULL, we don't need to pass root in.
Node LCA(Node p, Node q) {
int h1 = getHeight(p);
int h2 = getHeight(q);
// swap both nodes in case p is deeper than q.
if (h1 > h2) {
swap(h1, h2);
swap(p, q);
}
// invariant: h1 <= h2.
int dh = h2 - h1;
for (int h = 0; h < dh; h++)
q = q.parent;
while (p && q) {
if (p == q) return p;
p = p.parent;
q = q.parent;
}
return NULL; // p and q are not in the same tree
}
TreeNode findLCA(TreeNode root, TreeNode p, TreeNode q) {
// no root no LCA.
if(!root) {
return NULL;
}
// if either p or q is the root then root is LCA.
if(root==p || root==q) {
return root;
} else {
// get LCA of p and q in left subtree.
TreeNode l=findLCA(root->left , p , q);
// get LCA of p and q in right subtree.
TreeNode r=findLCA(root->right , p, q);
// if one of p or q is in leftsubtree and other is in right
// then root it the LCA.
if(l && r) {
return root;
}
// else if l is not null, l is LCA.
else if(l) {
return l;
} else {
return r;
}
}
}
// Finds the path from root node to given root of the tree, Stores the
// path in a vector path[], returns true if path exists otherwise false
bool findPath(Node root, ArrayList<Integer> path, int k)
{
// base case
if (root == null) return false;
// Store this node in path vector. The node will be removed if
// not in path from root to k
path.add(root.data);
// See if the k is same as root's key
if (root.data == k)
return true;
// Check if k is found in left or right sub-tree
if ( (root.left && findPath(root.left, path, k)) ||
(root.right && findPath(root.right, path, k)) )
return true;
// If not present in subtree rooted with root, remove root from
// path[] and return false
path.remove();
return false;
}
// Returns LCA if node n1, n2 are present in the given binary tree,
// otherwise return -1
int findLCA(Node root, int n1, int n2)
{
// to store paths to n1 and n2 from the root
ArrayList<Integer> path1, path2;
// Find paths from root to n1 and root to n1. If either n1 or n2
// is not present, return -1
if ( !findPath(root, path1, n1) || !findPath(root, path2, n2))
return -1;
// Compare the paths to get the first different value
int i;
for (i = 0; i < path1.size() && i < path2.size() ; i++)
if (path1[i] != path2[i])
break;
return path1[i-1];
}
TreeNode findFirstCommonAncestor(TreeNode root, int p, int q) {
if (root == null) {
return null;
}
if (root.value == p || root.value == q) {
return root;
}
if (root.value > p && root.value > q ) {
return findFirstCommonAncestor(root.left, p, q);
}
else if (root.value < p && root.value < q ) {
return findFirstCommonAncestor(root.right, p, q);
}
else {
return root;
}
}
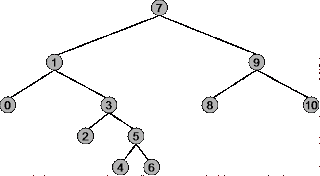
preorder(N *root)
{
if(root)
{
printf("Value : [%d]", root->value);
preorder(root->left);
preorder(root->right);
}
}

void iterativePreorder(node *root)
{
node *save[100];
int top = 0;
if (root == NULL)
{
return;
}
save[top++] = root;
while (top != 0)
{
root = save[--top];
printf("[%d] ", root->value);
if (root->right != NULL)
save[top++] = root->right;
if (root->left != NULL)
save[top++] = root->left;
}
}
void preOrderNonRecursive(node* root) {
if (!root) {
return;
}
Stack<node*> t = new Stack<node*>();
t.Push(root);
while (t.Size() > 0) {
node* top = t.Pop();
printf("%d", top->value);
if (top->right != null) {
t.Push(top->right);
}
if (top->left != null) {
t.Push(top->left);
}
}
}
Numbers are randomly generated and passed to a method. Write a program to find and maintain the median value as new values are generated.OR
You are given a stream of numbers which can be positive or negative. You are required to provide an operation FIND MEDIAN..which when invoked should be able return the median of the numbers in stream(in say O(1) time)
Find the rolling median?
Step 1: Add next item to one of the heaps
if next item is smaller than maxHeap root add it to maxHeap,
else add it to minHeap
Step 2: Balance the heaps (after this step heaps will be either balanced or
one of them will contain 1 more item)
if number of elements in one of the heaps is greater than the other by
more than 1, remove the root element from the one containing more elements and
add to the other one
if some one calls getMedian...then
If the heaps contain equal elements;
median = (root of maxHeap + root of minHeap)/2
Else
median = root of the heap with more elements
public static class maxComparator implements Comparator<Double> {
public int compare(Double o1, Double o2) {
return -o1.compareTo(o2);
}
}
static PriorityQueue<Double> minHeap = new PriorityQueue<Double>(11,
new maxComparator());
static PriorityQueue<Double> maxHeap = new PriorityQueue<Double>();
public static void addToHeap(double number) {
if (minHeap.size() == maxHeap.size()) {
if (minHeap.isEmpty())
minHeap.add(number);
else if (number > minHeap.peek())
maxHeap.add(number);
else { // number < minHeap.peek()
maxHeap.add(minHeap.poll());
minHeap.add(number);
}
} else if (minHeap.size() > maxHeap.size()) {
if (number > minHeap.peek())
maxHeap.add(number);
else { // number <= minHeap.peek()
maxHeap.add(minHeap.poll());
minHeap.add(number);
}
} else { // minHeap.size() < maxHeap.size()
if (number < maxHeap.peek())
minHeap.add(number);
else { // number >= maxHeap.peek()
minHeap.add(maxHeap.poll());
maxHeap.add(number);
}
}
}
public static double getMedian() {
if (minHeap.size() == maxHeap.size())
return (minHeap.peek() + maxHeap.peek()) / 2;
else if (minHeap.size() > maxHeap.size())
return minHeap.peek();
else
return maxHeap.peek();
}








void bubbleSort(int arr[], int n) {
bool swapped = true;
int j = 0;
int tmp;
while (swapped) {
swapped = false;
j++;
for (int i = 0; i < n - j; i++) {
if (arr[i] > arr[i + 1]) {
tmp = arr[i];
arr[i] = arr[i + 1];
arr[i + 1] = tmp;
swapped = true;
}
}
}
}
#include <iostream>
class BubbleSort
{
public:
BubbleSort(){}
~BubbleSort(){}
void sort(int arr[], int size);
};
void BubbleSort::sort(int arr[], int size)
{
//With every iteration in outer loop, the next maximum element is moved to it's correct position
for(int outerLoopIdx = 0; outerLoopIdx < size ; ++outerLoopIdx)
{
for(int innerLoopIdx = 0; innerLoopIdx < (size - outerLoopIdx - 1); ++innerLoopIdx)
{
//Comparing two subsequent elements OR bubble comparison
//Placing the larger element on the right
if(arr[innerLoopIdx] > arr[innerLoopIdx + 1])
{
int temp = arr[innerLoopIdx];
arr[innerLoopIdx] = arr[innerLoopIdx + 1];
arr[innerLoopIdx + 1] = temp;
}
}
}
}
void print(int arr[], int size)
{
for(int i = 0; i < size; ++i)
std::cout << arr[i] << " ";
std::cout << std::endl;
}
int main()
{
int arr[] = { 10, 65, 35, 25, 15, 75, 85, 45, 65 };
BubbleSort bs;
bs.sort(arr, 9);
print(arr, 9);
return 0;
}#include <iostream>
class BubbleSort
{
public:
BubbleSort(){}
~BubbleSort(){}
void sort(int arr[], int size);
};
void BubbleSort::sort(int arr[], int size)
{
//With every iteration in outer loop, the next maximum element is moved to it's correct position
for(int outerLoopIdx = 0; outerLoopIdx < size ; ++outerLoopIdx)
{
for(int innerLoopIdx = 0; innerLoopIdx < (size - outerLoopIdx - 1); ++innerLoopIdx)
{
//Comparing two subsequent elements OR bubble comparison
//Placing the larger element on the right
if(arr[innerLoopIdx] > arr[innerLoopIdx + 1])
{
int temp = arr[innerLoopIdx];
arr[innerLoopIdx] = arr[innerLoopIdx + 1];
arr[innerLoopIdx + 1] = temp;
}
}
}
}
void print(int arr[], int size)
{
for(int i = 0; i < size; ++i)
std::cout << arr[i] << " ";
std::cout << std::endl;
}
int main()
{
int arr[] = { 10, 65, 35, 25, 15, 75, 85, 45, 65 };
BubbleSort bs;
bs.sort(arr, 9);
print(arr, 9);
return 0;
}
import org.junit.Assert;
import org.junit.Test;
class GenericBubbleSorter<T extends Comparable<T>>
{
public void sort(T[] elems) {
int size = elems.length;
for (int outerLoopIdx = 0; outerLoopIdx < size; ++outerLoopIdx) {
for (int innerLoopIdx = 0; innerLoopIdx < (size - outerLoopIdx - 1); ++innerLoopIdx) {
if (elems[innerLoopIdx].compareTo(elems[innerLoopIdx + 1]) > 0) {
T temp = elems[innerLoopIdx];
elems[innerLoopIdx] = elems[innerLoopIdx + 1];
elems[innerLoopIdx + 1] = temp;
}
}
}
}
}
public class BubbleSortTester
{
private String[] unsortedNames = new String[] {
"Pankaj",
"Paresh",
"Ankit",
"Sankalp",
"Aditya",
"Prem",
"Rocket",
"Singh",
"Alabama",
"Alaska",
"Animal" };
private String[] sortedNames = new String[] {
"Aditya",
"Alabama",
"Alaska",
"Animal",
"Ankit",
"Pankaj",
"Paresh",
"Prem",
"Rocket",
"Sankalp",
"Singh" };
@Test
public void testStringSort() {
GenericBubbleSorter<String> bs = new GenericBubbleSorter<String>();
bs.sort(unsortedNames);
Assert.assertArrayEquals(unsortedNames, sortedNames);
}
}
#include <iostream>
using namespace std;
struct node
{
int info;
struct node *next;
};
struct node *top;
int empty()
{
return((top == NULL)? 1:0);
}
void push(int n)
{
struct node *p;
p=new node;
if(p!=NULL)
{
p->info=n;
p->next=top;
top=p;
}
else
cout<<"Not inserted,No memory available";
}
int pop()
{
struct node *temp;
int x;
x=top->info;
temp=top;
top=top->next;
free(temp);
return(x);
}
void print()
{
int i =0;
struct node * temp;
temp = top;
cout<<"\n\t\t";
if(temp==NULL)
cout<<"\n\t\tNo elements\n";
else
{
while(temp!=NULL)
{
int info = temp->info;
cout<info<<" ";
temp=temp->next;
}
cout<<"End of List<<"\n";
}
}
class ListNode<E>
{
E data;
ListNode<E> next;
}
public class Stack<E>
{
private ListNode<E> m_head;
public Stack () {
m_head = null;
}
public void push (E n) {
ListNode<E> tmp = getNewNode();
tmp.data = n;
ListNode<E> oHead = m_head;
m_head = tmp;
m_head.next = oHead;
}
public void pop () {
if (isEmpty()) throw new NoSuchElementException("Stack is Empty");
m_head = m_head.next;
}
public E top () {
return m_head.data;
}
public boolean isEmpty () {
return m_head == null;
}
private ListNode<E> getNewNode () {
return new ListNode<E>();
}
}
import junit.framework.Assert;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class StackTest
{
private String[] elems = new String[] { "A", "B", "C" };
private Stack<String> stack = new Stack<String>();
@Before
public void setup () {
for (String str : elems)
{
stack.push(str);
}
}
@After
public void destroy () {
while (stack.isEmpty() == false)
{
stack.pop();
}
}
@Test
public void testTop () {
Assert.assertEquals(stack.top(), "C");
}
@Test
public void testPush () {
Assert.assertEquals(stack.top(), "C");
stack.pop();
Assert.assertEquals(stack.top(), "B");
stack.pop();
Assert.assertEquals(stack.top(), "A");
}
}
Please let us know the feedback.
#include <conio.h> using namespace std; #include <iostream> #include <math> void radixsort(int num[],int n) { int queue[10][10],inc[10],i,j,k,c,exp; for(i=0;i<4;i++) { exp=pow(10,i); for(j=0;j<10;j++) inc[j]=-1; for(j=0;j<10;j++) { k=(num[j]/exp)%10; inc[k]++; queue[k][inc[k]]=num[j]; } for(k=0,c=0;k<10;k++) { j=0; if(inc[k]!=-1) while(j<=inc[k]) { num[c++]=queue[k][j]; j++; } } } }
int main() { int num[10]; cout<<"Enter the elements to be sorted :\n"; for(int i=0;i<10;i++) cin>>num[i]; radixsort(num,10); cout<<"The elemments in sorted order are :\n"; for(int i=0;i<10;i++) cout<<<" "; getch(); }

QuickSort(Array a, length n)
if n = 1 return
p = ChoosePivot(a, n)
Parition a around p
QuickSort(first part)
QuickSort(second part)

Partition(a,left,right)
{
p=a[left];
i=left+1;
for(j=l+1;j<right;j++)
{
if(a[j]<p)
swap(a[j],a[i]);
}
i++;
swap(a[left],a[i-1]);
}
Lets dry run this version


Partition(a,left,right)
{
p=a[left];
l=left+1;
while (l < r) {
while (l < right && a[l] < p) l++;
while (r > left && a[r] >= p) r--;
if (l < r) swap a[l],a[r]
}
}







int Partition(int *darr, int lb, int ub)
{
int a; /* key holder */
int up, down;
int temp;
a = darr[lb];
up = ub;
down = lb;
while (down < up)
{
while (darr[down] <= a) /* scan the keys from left to right */
down++;
while (darr[up] > a) /* scan the keys from right to left */
up--;
if (down < up)
{
temp = darr[down]; /* interchange records */
darr[down] = darr[up];
darr[up] = temp;
}
}
darr[lb] = darr[up]; /* interchange records */
darr[up] = a;
return up;
}
void quick_sort(int *darr, int lb, int ub)
{
/* temporary variable, used in swapping */
int up;
if (lb >= ub)
return;
up = Partition(darr,lb,ub);
quick_sort(darr, lb, up-1); /* recursive call - sort first subtable */
quick_sort(darr, up+1, ub); /* recursive call - sort second subtable */
}




mergeSort(arr)
{
list1 = arr(0-n/2);
list2 = arr(n/2+1,n);
list1 = mergeSort(list1);
list2 = mergeSort(list2);
}
#define MAX 20
void mergesort(int *,int);
void main()
{
int x[MAX],n,j,i;
char ans;
clrscr();
{
printf("\nEnter The Length Of The Array\t: ");
scanf("%d",&n);
for(i=0;i< n;i++)
{
printf("Enter Element %d\t: ",i+1);
scanf("%d",&x[i]);
}
mergesort(x,n);
printf("\n\t│ Sorted Array :\t\t\t│\n\t│");
for(i=0;i< n;i++)
printf("%d\t",x[i]);
}
printf("│");
getch();
}
void mergesort(int x[],int n)
{
int sub[MAX];
int i,j,k,list1,list2,u1,u2,size=1;
while(size< n)
{
list1=0;
k=0;
while((list1+size)< n)
{
list2=list1+size;
u1=list2-1;
u2=((list2+size-1)< n)?(list2+size-1):(n-1);
for(i=list1,j=list2;i< =u1 &&amp; j< =u2;k++)
if(x[i]< =x[j])
sub[k]=x[i++];
else
sub[k]=x[j++];
for(;i< =u1;k++)
sub[k]=x[i++];
for(;j< =u2;k++)
sub[k]=x[j++];
list1=u2+1;
}
for(i=list1;k< n;i++)
sub[k++] = x[i];
for(i=0;i< n;i++)
x[i] =sub[i];
size *= 2;
}
}